
Authors:
(1) Dustin Podell, Stability AI, Applied Research;
(2) Zion English, Stability AI, Applied Research;
(3) Kyle Lacey, Stability AI, Applied Research;
(4) Andreas Blattmann, Stability AI, Applied Research;
(5) Tim Dockhorn, Stability AI, Applied Research;
(6) Jonas Müller, Stability AI, Applied Research;
(7) Joe Penna, Stability AI, Applied Research;
(8) Robin Rombach, Stability AI, Applied Research.
Table of Links
2.4 Improved Autoencoder and 2.5 Putting Everything Together
Appendix
D Comparison to the State of the Art
E Comparison to Midjourney v5.1
F On FID Assessment of Generative Text-Image Foundation Models
G Additional Comparison between Single- and Two-Stage SDXL pipeline
2 Improving Stable Diffusion
In this section we present our improvements for the Stable Diffusion architecture. These are modular, and can be used individually or together to extend any model. Although the following strategies are implemented as extensions to latent diffusion models (LDMs) [38], most of them are also applicable to their pixel-space counterparts.
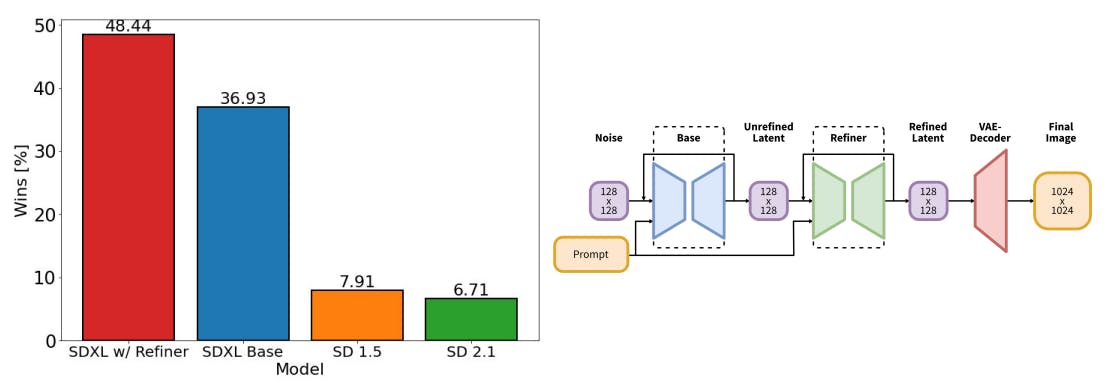
![Figure 1: Left: Comparing user preferences between SDXL and Stable Diffusion 1.5 & 2.1. While SDXL already clearly outperforms Stable Diffusion 1.5 & 2.1, adding the additional refinement stage boosts performance. Right: Visualization of the two-stage pipeline: We generate initial latents of size 128 × 128 using SDXL. Afterwards, we utilize a specialized high-resolution refinement model and apply SDEdit [28] on the latents generated in the first step, using the same prompt. SDXL and the refinement model use the same autoencoder.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-38830hm.png)
This paper is available on arxiv under CC BY 4.0 DEED license.