

Authors:
(1) Dustin Podell, Stability AI, Applied Research;
(2) Zion English, Stability AI, Applied Research;
(3) Kyle Lacey, Stability AI, Applied Research;
(4) Andreas Blattmann, Stability AI, Applied Research;
(5) Tim Dockhorn, Stability AI, Applied Research;
(6) Jonas Müller, Stability AI, Applied Research;
(7) Joe Penna, Stability AI, Applied Research;
(8) Robin Rombach, Stability AI, Applied Research.
Table of Links
2.4 Improved Autoencoder and 2.5 Putting Everything Together
Appendix
D Comparison to the State of the Art
E Comparison to Midjourney v5.1
F On FID Assessment of Generative Text-Image Foundation Models
G Additional Comparison between Single- and Two-Stage SDXL pipeline
G Additional Comparison between Single- and Two-Stage SDXL pipeline
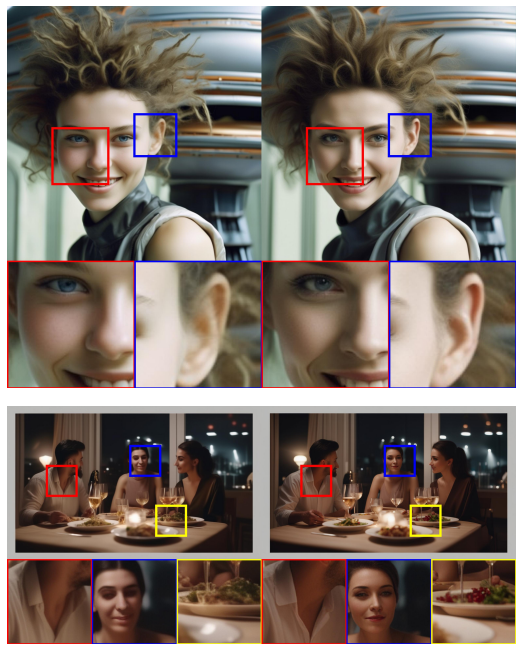
H Comparison between SD 1.5 vs. SD 2.1 vs. SDXL
![Figure 14: Additional results for the comparison of the output of SDXL with previous versions of Stable Diffusion. For each prompt, we show 3 random samples of the respective model for 50 steps of the DDIM sampler [46] and cfg-scale 8.0 [13]](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-r38307m.png)
![Figure 15: Additional results for the comparison of the output of SDXL with previous versions of Stable Diffusion. For each prompt, we show 3 random samples of the respective model for 50 steps of the DDIM sampler [46] and cfg-scale 8.0 [13].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-at930nm.png)
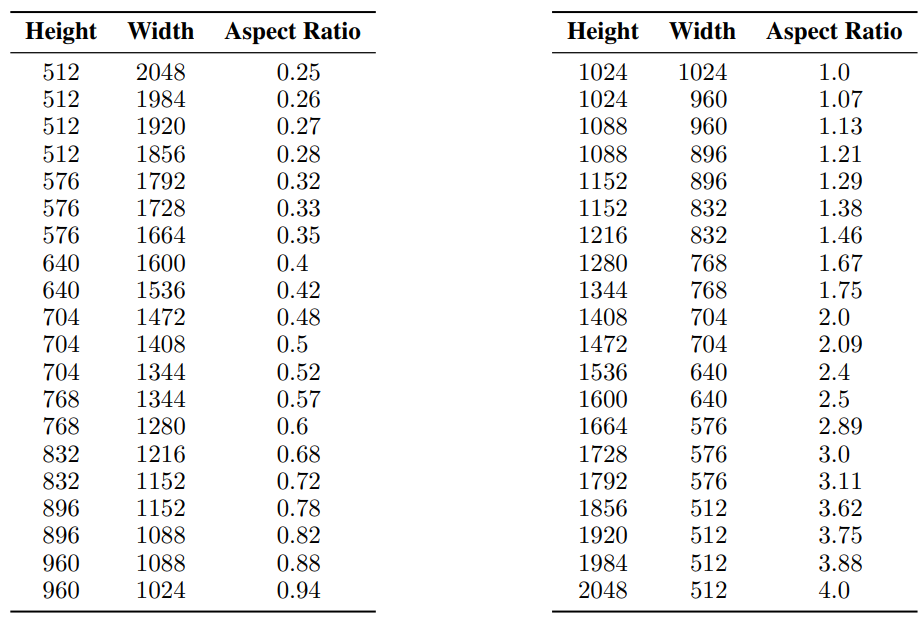
I Multi-Aspect Training Hyperparameters
We use the following image resolutions for mixed-aspect ratio finetuning as described in Sec. 2.3.
J Pseudo-code for Conditioning Concatenation along the Channel Axis

This paper is available on arxiv under CC BY 4.0 DEED license.