
Authors:
(1) Dustin Podell, Stability AI, Applied Research;
(2) Zion English, Stability AI, Applied Research;
(3) Kyle Lacey, Stability AI, Applied Research;
(4) Andreas Blattmann, Stability AI, Applied Research;
(5) Tim Dockhorn, Stability AI, Applied Research;
(6) Jonas Müller, Stability AI, Applied Research;
(7) Joe Penna, Stability AI, Applied Research;
(8) Robin Rombach, Stability AI, Applied Research.
Table of Links
2.4 Improved Autoencoder and 2.5 Putting Everything Together
Appendix
D Comparison to the State of the Art
E Comparison to Midjourney v5.1
F On FID Assessment of Generative Text-Image Foundation Models
G Additional Comparison between Single- and Two-Stage SDXL pipeline
F On FID Assessment of Generative Text-Image Foundation Models
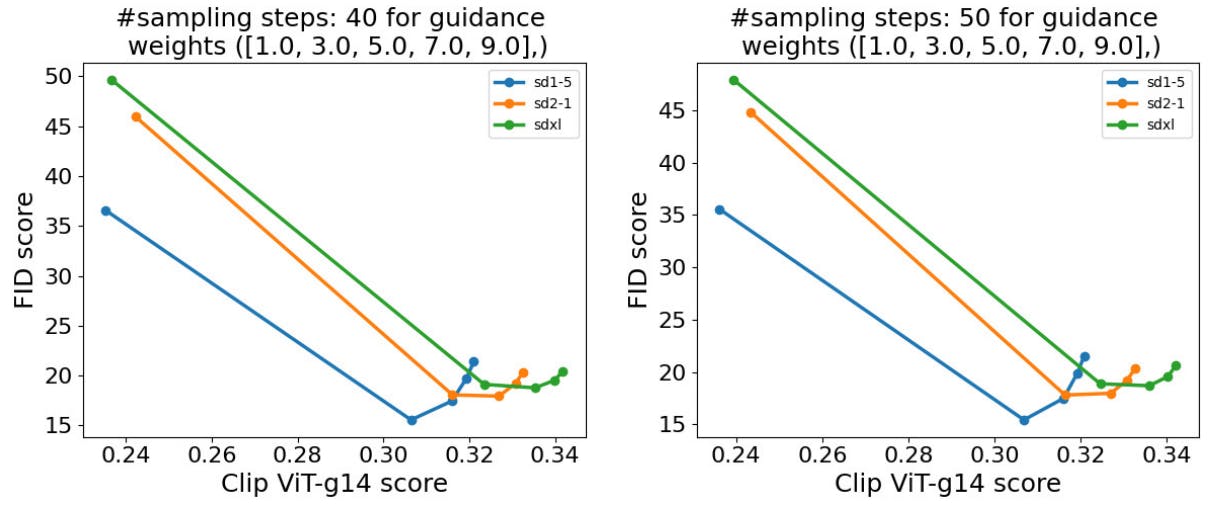
![Figure 12: Plotting FID vs CLIP score for different cfg scales. SDXL shows only slightly improved textalignment, as measured by CLIP-score, compared to previous versions that do not align with the judgement of human evaluators. Even further and similar as in [23], FID are worse than for both SD-1.5 and SD-2.1, while human evaluators clearly prefer the generations of SD-XL over those of these previous models.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-kt830ly.png)
Throughout the last years it has been common practice for generative text-to-image models to assess FID- [12] and CLIP-scores [34, 36] in a zero-shot setting on complex, small-scale text-image datasets of natural images such as COCO [26]. However, with the advent of foundational text-to-image models [40, 37, 38, 1], which are not only targeting visual compositionality, but also at other difficult tasks such as deep text understanding, fine-grained distinction between unique artistic styles and especially a pronounced sense of visual aesthetics, this particular form of model evaluation has become more and more questionable. Kirstain et al. [23] demonstrates that COCO zero-shot FID is negatively correlated with visual aesthetics, and such measuring the generative performance of such models should be rather done by human evaluators. We investigate this for SDXL and visualize FID-vs-CLIP curves in Fig. 12 for 10k text-image pairs from COCO [26]. Despite its drastically improved performance as measured quantitatively by asking human assessors (see Fig. 1) as well as qualitatively (see Fig. 4 and Fig. 14), SDXL does not achieve better FID scores than the previous SD versions. Contrarily, FID for SDXL is the worst of all three compared models while only showing slightly improved CLIP-scores (measured with OpenClip ViT g-14). Thus, our results back the findings of Kirstain et al. [23] and further emphasize the need for additional quantitative performance scores, specifically for text-to-image foundation models. All scores have been evaluated based on 10k generated examples.
This paper is available on arxiv under CC BY 4.0 DEED license.