
Authors:
(1) Dustin Podell, Stability AI, Applied Research;
(2) Zion English, Stability AI, Applied Research;
(3) Kyle Lacey, Stability AI, Applied Research;
(4) Andreas Blattmann, Stability AI, Applied Research;
(5) Tim Dockhorn, Stability AI, Applied Research;
(6) Jonas Müller, Stability AI, Applied Research;
(7) Joe Penna, Stability AI, Applied Research;
(8) Robin Rombach, Stability AI, Applied Research.
Table of Links
2.4 Improved Autoencoder and 2.5 Putting Everything Together
Appendix
D Comparison to the State of the Art
E Comparison to Midjourney v5.1
F On FID Assessment of Generative Text-Image Foundation Models
G Additional Comparison between Single- and Two-Stage SDXL pipeline
D Comparison to the State of the Art

E Comparison to Midjourney v5.1
E.1 Overall Votes
To asses the generation quality of SDXL we perform a user study against the state of the art text-toimage generation platform Midjourney[1]. As the source for image captions we use the PartiPrompts (P2) benchmark [53], that was introduced to compare large text-to-image model on various challenging prompts.
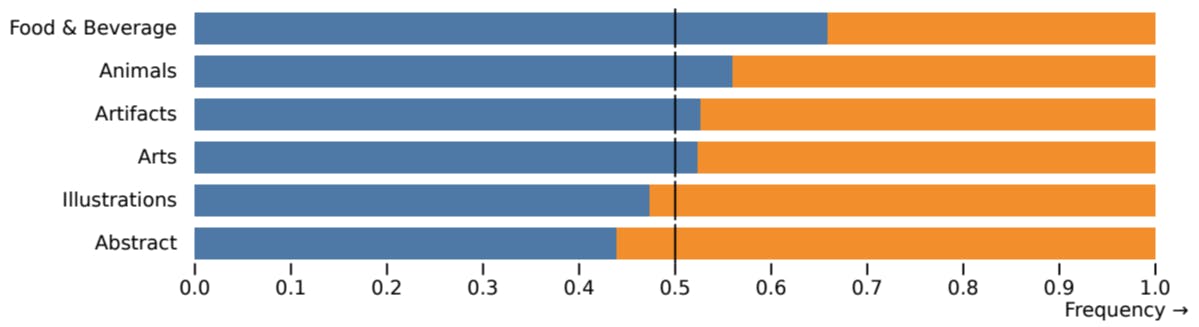
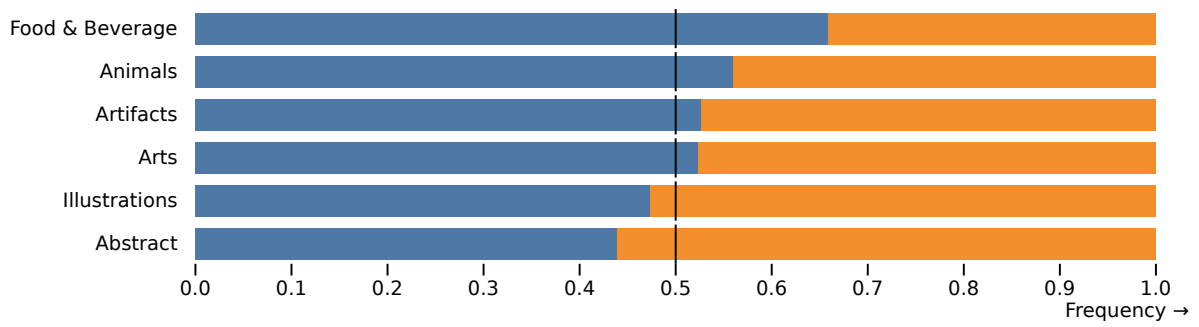
For our study, we choose five random prompts from each category, and generate four 1024 × 1024 images by both Midjourney (v5.1, with a set seed of 2) and SDXL for each prompt. These images were then presented to the AWS GroundTruth taskforce, who voted based on adherence to the prompt. The results of these votes are illustrated in Fig. 9. Overall, there is a slight preferance for SDXL over Midjourney in terms of prompt adherence.

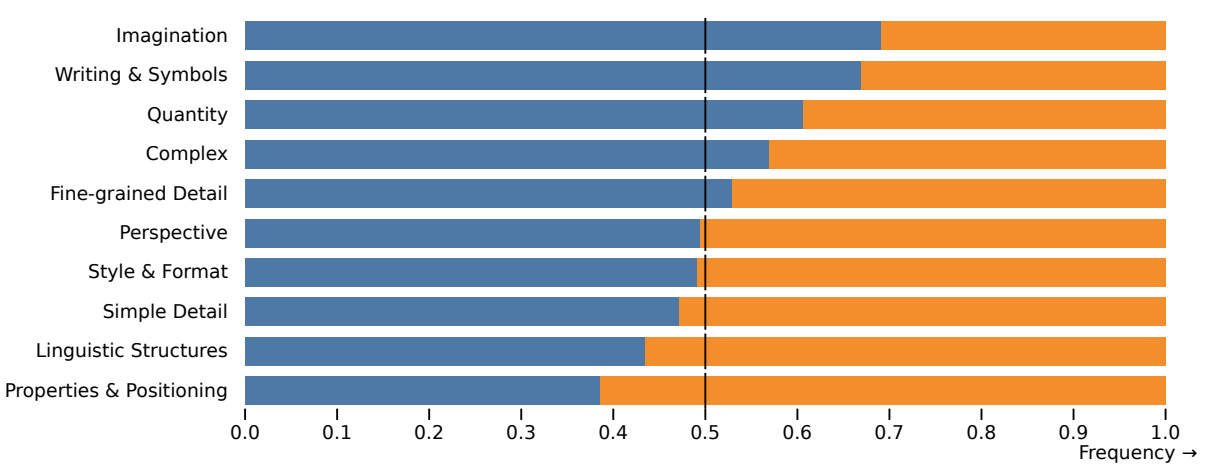
E.2 Category & challenge comparisons on PartiPrompts (P2)
Each prompt from the P2 benchmark is organized into a category and a challenge, each focus on different difficult aspects of the generation process. We show the comparisons for each category (Fig. 10) and challenge (Fig. 11) of P2 below. In four out of six categories SDXL outperforms Midjourney, and in seven out of ten challenges there is no significant difference between both models or SDXL outperforms Midjourney.
This paper is available on arxiv under CC BY 4.0 DEED license.