
Authors:
(1) Dustin Podell, Stability AI, Applied Research;
(2) Zion English, Stability AI, Applied Research;
(3) Kyle Lacey, Stability AI, Applied Research;
(4) Andreas Blattmann, Stability AI, Applied Research;
(5) Tim Dockhorn, Stability AI, Applied Research;
(6) Jonas Müller, Stability AI, Applied Research;
(7) Joe Penna, Stability AI, Applied Research;
(8) Robin Rombach, Stability AI, Applied Research.
Table of Links
2.4 Improved Autoencoder and 2.5 Putting Everything Together
Appendix
D Comparison to the State of the Art
E Comparison to Midjourney v5.1
F On FID Assessment of Generative Text-Image Foundation Models
G Additional Comparison between Single- and Two-Stage SDXL pipeline
C Diffusion Models

Sampling. In practice, this iterative denoising process explained above can be implemented through the numerical simulation of the Probability Flow ordinary differential equation (ODE) [47]

Classifier-free guidance. Classifier-free guidance [13] is a technique to guide the iterative sampling process of a DM towards a conditioning signal c by mixing the predictions of a conditional and an unconditional model
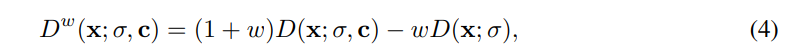
where w ≥ 0 is the guidance strength. In practice, the unconditional model can be trained jointly alongside the conditional model in a single network by randomly replacing the conditional signal c with a null embedding in Eq. (3), e.g., 10% of the time [13]. Classifier-free guidance is widely used to improve the sampling quality, trading for diversity, of text-to-image DMs [30, 38]
This paper is available on arxiv under CC BY 4.0 DEED license.